



Long Live Small, Fast, Actionable Insights!
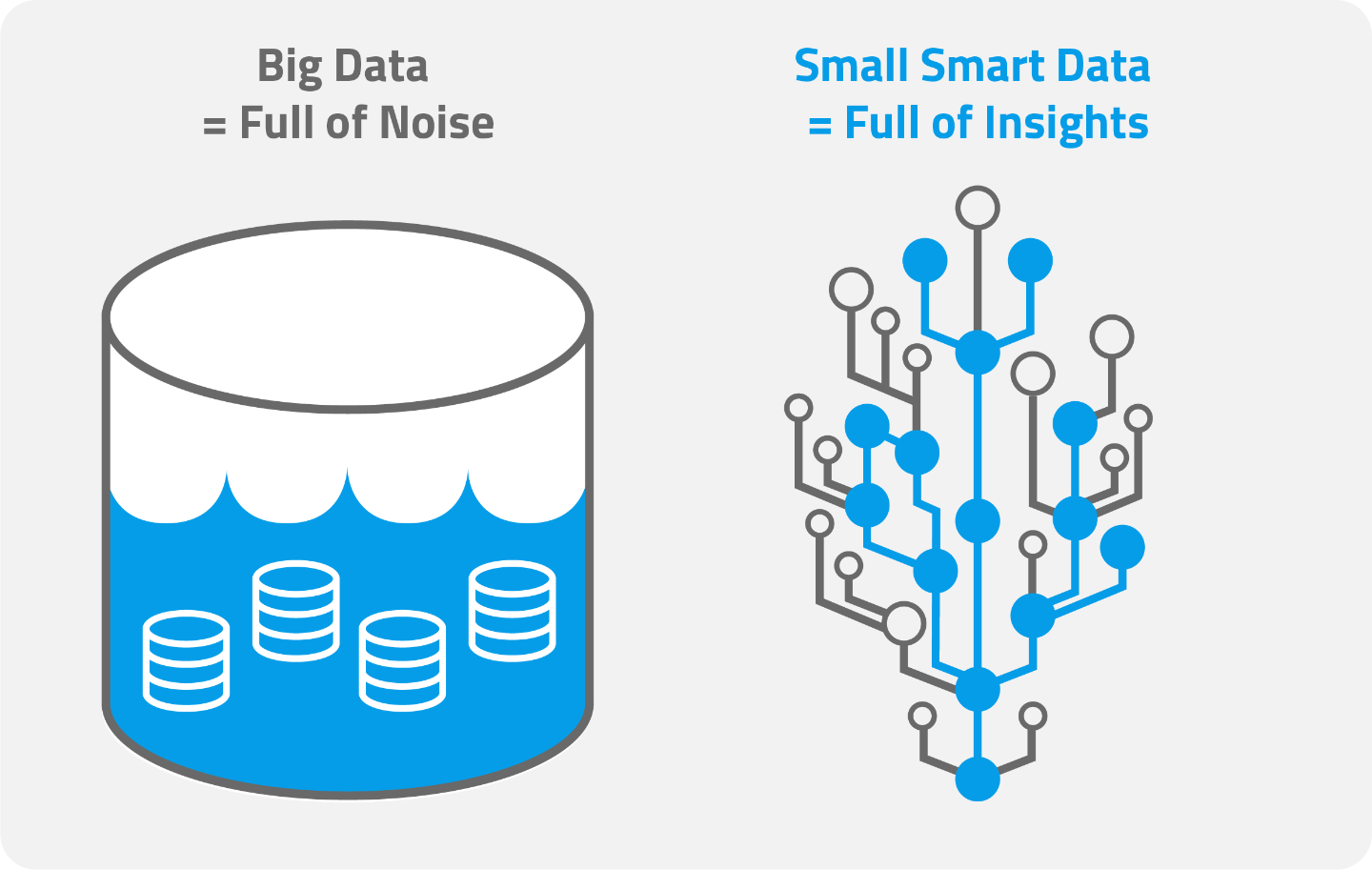
Big data is everywhere. Organizations are being advised to hoard it, and to do everything they can to derive actionable insights from it. This article will argue that this approach puts the cart before the horse.
First, let’s start with a revelation. Despite the hype and despite everything you’ve been told about big data as a necessary precursor to achieving valuable business insights, it has by and large failed to deliver on its promises.
All the data in the world means nothing, if you can’t make sense of it. And that’s the hard part. Even Gartner predicts that through 2017, 60% of big data projects will fail to go beyond piloting and experimentation, and ultimately will be abandoned.
High Risk and Cost of Failure in Data Analytics
Part of the reason for this failure is that organizations rush to accumulate and analyze as much data as possible, all at once, and without much of a plan. This usually ends terribly. It’s not unusual anymore for organizations to house multiple petabytes of data. These compulsive data hoarders pathologically store any data they can get their hands on, thinking that the more data they have, the better off they will be, the more intelligent they will be, and the higher the quality and number of insights they can glean from it.
But starting big can lead to an overwhelmed team, not to mention huge costs. These organizations won’t be able to see the insights for the data, so to speak. With more data and more capabilities to rationalize data across silos, it can feel like there are more opportunities than there are resources to exploit them.
The problem is exacerbated by the fact that traditional approaches often fall short. Heavy duty enterprise business intelligence (BI) tools, central data warehouses, etc., designed to analyze big data sets, take years and cost millions to implement (something your BI service provider won’t tell you at the outset).
These heavy data warehouses can pay off. But when they don’t, the cost of failure is high. In a survey of more than 500 executives by McKinsey Analytics, 86% of respondents reported that their organizations were only somewhat effective at meeting the goals they set for their data and analytics initiatives.
The moral of the story? Hoarding big data is not a prerequisite for smart insights.
A Shorter, Nimbler Path to Insight: Follow the Breadcrumbs!
The truth is, for many organizations, starting small is a much more fruitful (and lower cost) exercise than bringing in heavyweight tools and consultants. Time and again we have seen some of the most valuable business insights derived from surprisingly small data sets. It’s time to focus, not on big data, but on the right data at the right time, and find a way to ask the right questions of that data.
It’s an approach to data analytics that we replicated from our best practices in software product development. Focus on delivering an MVP as fast as you can, and iterate from there. In this case, MVP does not stand for Minimal Viable Product, but Minimal Viable PREDICTION.
The MVP approach challenges traditional perceptions and established norms of big data and data analytics. The notion of having to assemble data, at any cost, is an extreme one. Instead of eating the entire elephant at once (your mouth is too small and you’ll choke), we recommend a low-risk approach to data analytics that a successful start-up might take. It is grounded in best-in-class software development methodologies. Here’s how it breaks down:
Start with focusing only on the #1 problem you want to solve - Instead of assembling all your data, disregard the noise and assemble only the data that correlates with your number one problem.
Once you’ve established your primary problem, work backwards from there identifying other related data, and follow the data breadcrumbs that lead to actionable outcomes. For example, you may start with understanding and predicting customer complaints - something that can have a very real impact on your revenue and profits. So, you’d assemble complaints data. Your next data breadcrumb might be customer service representative data, a potential reason for complaints. Another set of data could be transaction size by customer. Easy enough so far, and guess what? You may already be halfway there or more! Perhaps a single customer representative evokes unusually high numbers of customer complaints. But you can further query the data to understand whether transaction size shows correlation and predictability of customer complaints in association with that customer service representative.
You have just reached MVP status – you’re a Most Valuable Player having created a Minimal Viable Prediction! This sounds straightforward, but it can be tempting to jump into the data lake in front of you instead of just following small, relevant, iteratively assembled data breadcrumbs.
This approach also goes back to the earlier point about not being a data hoarder. Data becomes dated – fast. Make a point of spring-cleaning your data on a regular basis so that you avoid a glut of irrelevant data.
Iterate, constantly – As with software product development, don’t waste time trying to find the ultimate product (or in our case, the Answer to the Ultimate Question of Revenue, Profit, and Everything). Predictive analytics is a process of trial and error. There is a tendency in traditional data analytics to keep hoarding and trying to analyze all that data at the same time. Instead, focus, focus, focus, and iterate, iterate, iterate.
Start with prioritizing all the problems you might be able to solve with data analytics. Rank them by a) potential business impact and b) ease of assembling the first set of data. Then pick the highest-ranked problem, and follow the breadcrumbs. If you hit a dead end, retrace your steps and follow the next set of data breadcrumbs. Do it deliberately and with focus. Don’t get distracted. Just because you could easily assemble another set of data doesn’t mean that you should. Don’t muddle your quest to predict the solution to business problem number one. The more self-discipline you can demonstrate in pruning your data tree and avoid analyzing too much at once, the easier it is to generate insights and achieve a better outcome. As you continue to iterate, include more data, where and when it’s relevant, and only then.
Keep refining – Once you’ve solved your number one problem and have your first MVP, refine it again and again so you have an ongoing stream of actionable, affordable predictions. Here’s an example in which you operate a trucking company. Your number one headache is customer complaints. So your first data set includes all your complaint records. Your second tier of data may include a list of drivers and their HR records, shift schedules, truck inventory, trips taken, weather data, road condition data, etc. You dig into that data and find that weather and road conditions have no impact on complaints. However, surprise, you find that marital status has the highest impact! So, you decide not to hire married drivers or adjust your training methods. This is just an example and by no means a recommendation that you violate anti-discrimination laws! But you get the picture. The point is you are on the way to establishing a methodical process that iteratively solves your number one headache. You can now focus on the business problem ranked second and iterate, again and again.
This means investing time and changing mindsets inside and outside the organization to dismantle ingrained dogma that data analytics is an “all-or-nothing” big budget investment and encouraging a leap of faith to go another way.
By adopting the principles used in software development – starting small with a self-imposed incremental budget (why spend so much money, if you don’t have to?) and growing from there – you’ll realize results faster, cheaper, and without the risk of throwing millions of dollars and thousands of man hours at a heavyweight solution, where the probability of success is low.
Look to the Cloud as an Enabler
Cloud-based pay-as-you-go tools, such as Microsoft’s Power BI, are ideal companions for this approach, at least as a starting point. Today, data management, analysis, and visualization tools – all in convenient out-of-the-box, cloud-based packages – are making it more feasible for organizations, small and large, to become data savvy. And they’re doing it without the need to have multiple specialists on-hand and at a much lower price point. As you grow you may need to add-on additional functionality or move to more powerful tools – just don’t start there.
Follow the Data Breadcrumbs to Success
What does success look like? Once you have your first MVP, you are already more successful than 50% of other big data projects out there. Using our approach, we’ve seen clients reach that point in month two or three, not year two or three. By only focusing on the relevant data breadcrumbs and starting small, it becomes much easier to gauge whether you’re on the right track and correct any mistakes relatively cheaply.
Have the Courage to Go Against the Flow
Ok, so we have flipped the way organizations approach data analytics on its head. But having the courage to go against the flow by adopting such an agile, nimble approach to big data analysis can pay dividends. With self-discipline, focus, and a readiness to throw irrelevant data, no matter how “big”, out the window, the opportunity to make smarter, data-driven decisions and even monetize your data has a much higher probability of success!